2. Experiment
Experimentation is fundamental to machine learning, but it can be overwhelming when you have not worked in machine translation before.
To help you get started, here are two examples:
1. Choose Experiment Platform
You can choose your preferred platform for conducting experiments, including local environments like Jupyter Notebooks, or online platforms such as Google Colab and Kaggle. Cloud platforms are also an option if they fit your project needs.
It's important to note that the evaluation criteria for this competition include Cost as a significant (25% of the score) factor. Therefore, when designing your model and selecting your training instance, consider the potential costs to ensure they align with the competition’s budgetary guidelines.
2. Get the Dataset
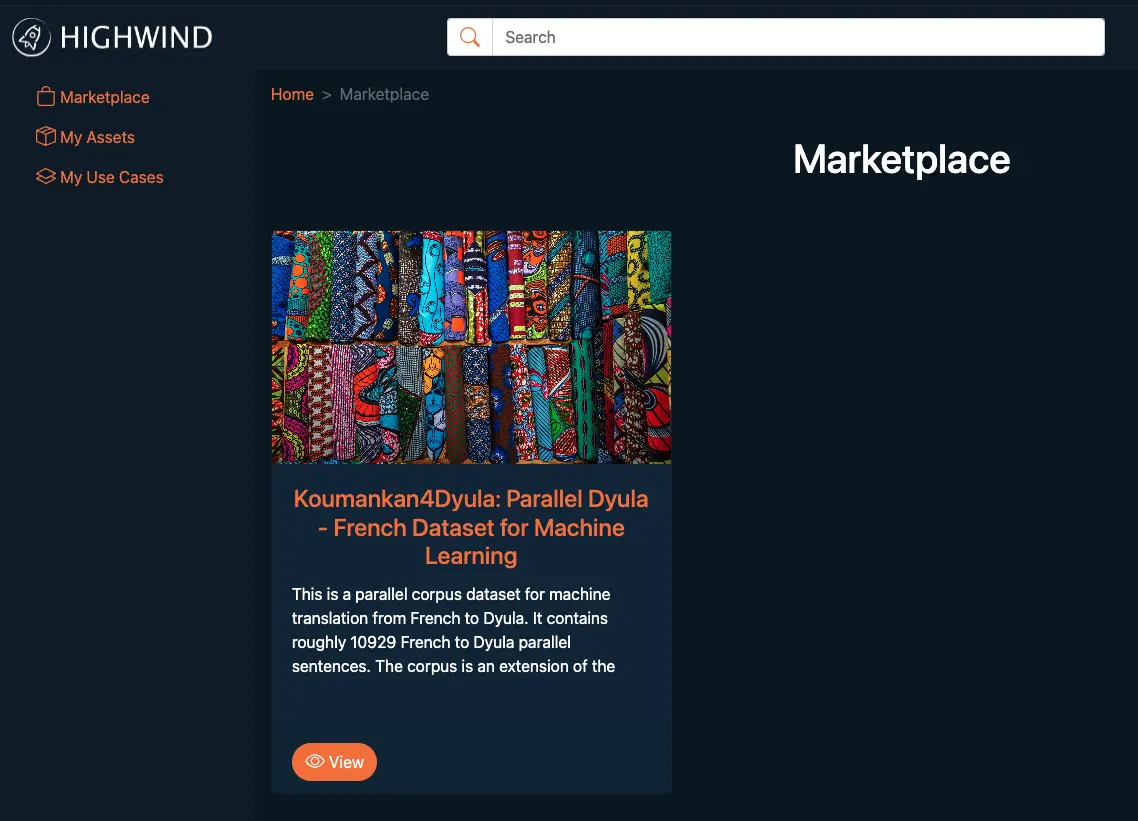
There are various Use Cases offered on the Highwind Marketplace, such as datasets, models, and even machine learning pipelines.
For this competition, we have pre-loaded the competition dataset (Parallel Dyula-French Dataset for Machine Learning) for you.
2.1 Purchase a Dataset Use Case
- Sign in to Highwind.
- Step 1: Navigate to the Highwind
Marketplaceon the left pane of the screen. - You will see the competition dataset available for purchase.
- Step 2: Click on the
viewbutton of the use case - Step 3: Click on the
purchasebutton of the use case - Step 4: Proceed to click on the
purchase (USD)button of the use case. The USD amount will vary based on the Use Case. - Once successfully purchased, you can navigate to the
My Use Casessection on the left pane of the screen, where the purchased Use Case will now be displayed as shown in the snippet below.>

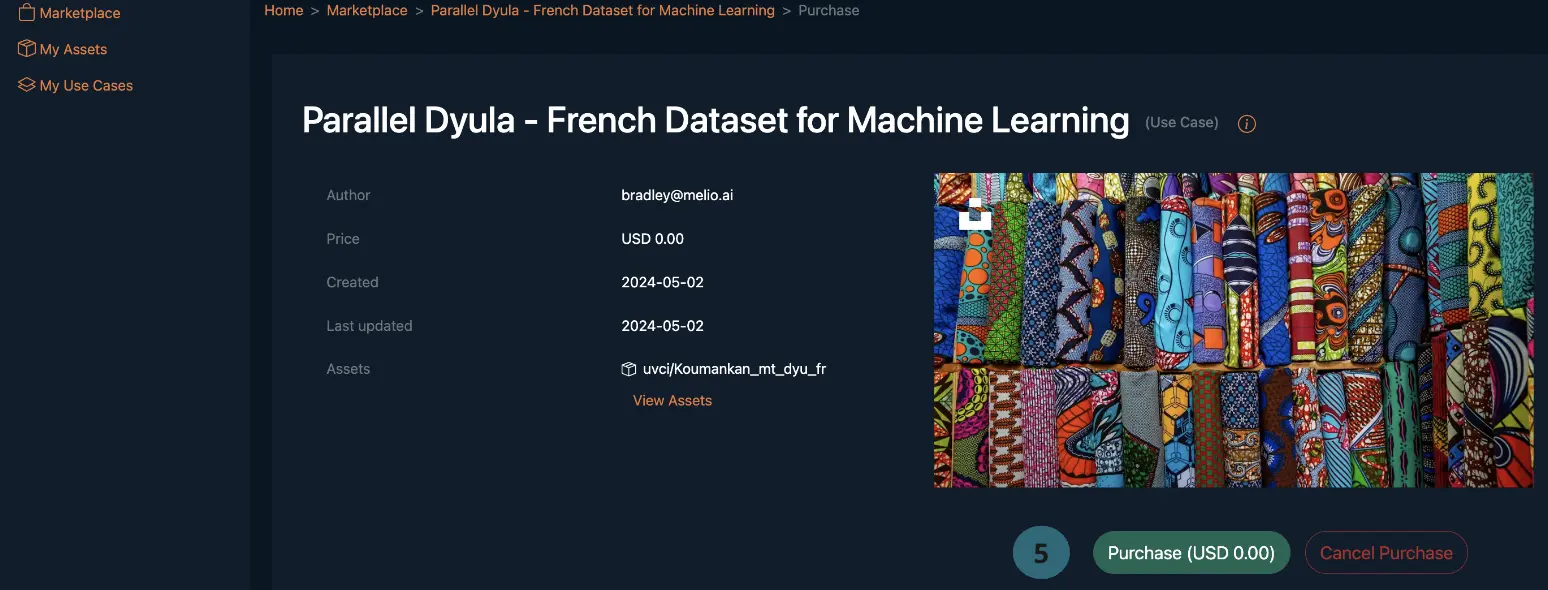
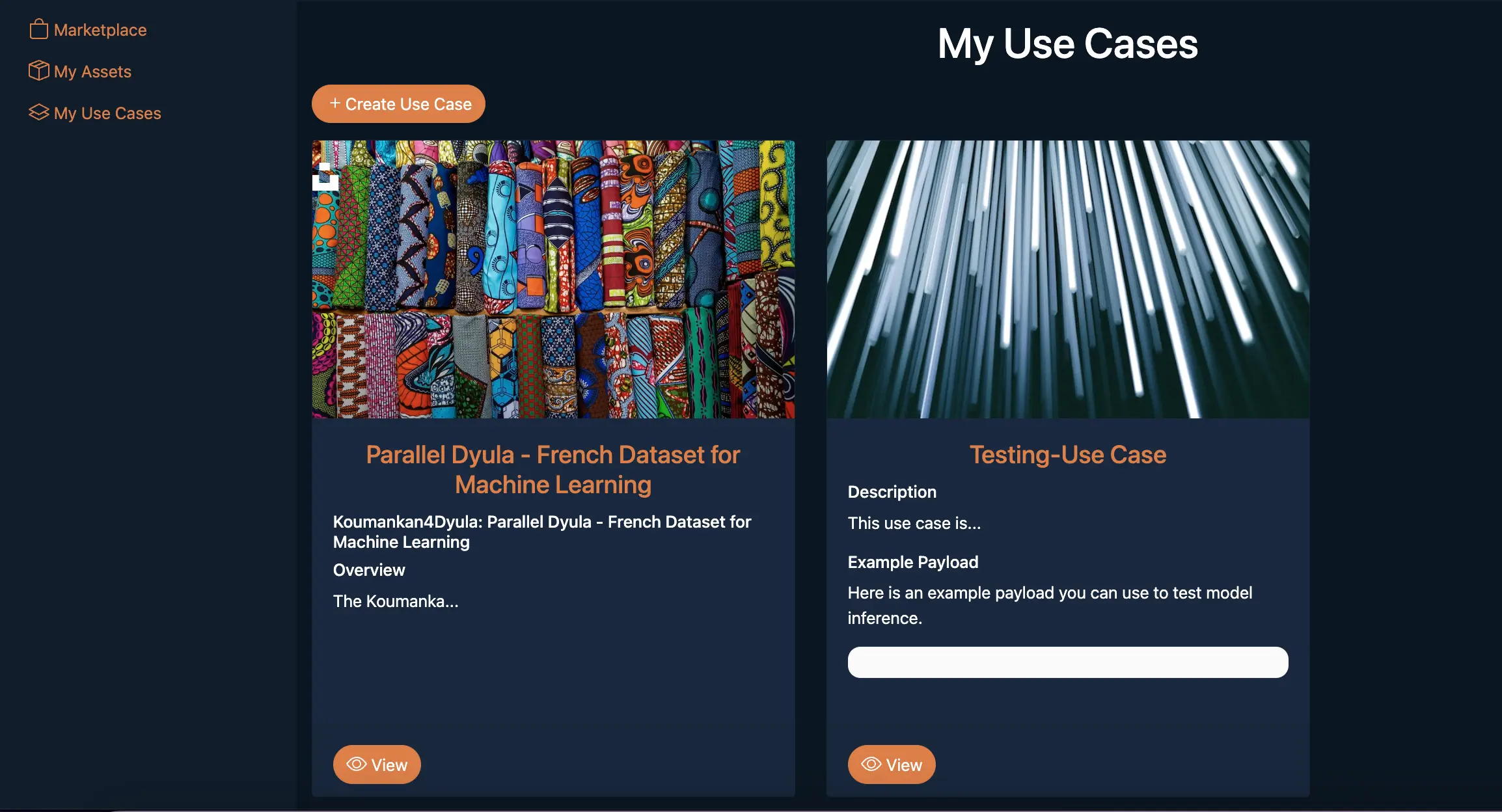
Don't worry, the Dataset is free and open-source, so we set the Purchasing price to $0.
2.2 Download the Dataset
- After purchasing the
Dataset Use Case, you can proceed to download theDatasetfor use. - Step 1: Navigate to the
My Assetspage on the left pane of the screen. - Step 2: Select the Dataset Use Case purchased and click on
view - Step 3: Scroll to the bottom of the page to the section titled
Asset Files - Step 4: Select the button titled
Downloadto proceed to download theDatasetfor use as shown below. - Please note that the contents are not comma-separated but pipe-separated (with the delimiter being "|"). You can load it as shown below:

import pandas as pd
train_df = pd.read_csv("/path/to/train-00000-of-00001.csv", delimiter="|", index_col=0)
3. Run Experiments
You are encouraged to explore the various stages of experimentation typically encountered in machine learning projects. The following tasks can provide some inspiration:
-
Model Training: Participants are encouraged to explore various neural network architectures such as RNNs, CNNs, and Transformer models. Experimenting with sequence-to-sequence models and attention mechanisms could be key to achieving optimal translation accuracy.
-
Hyperparameter Tuning: Tuning hyperparameters such as encoder-decoder layers, attention heads, and learning rates can significantly impact the effectiveness of the translation model. Participants should explore different settings to optimize translation quality and efficiency.
-
Data Preprocessing: Preprocessing tasks for machine translation include tokenization, handling of out-of-vocabulary words, and sentence alignment. Normalization of text data to handle various language constructs and cleaning noisy datasets are critical to prepare data for effective translation.
-
Feature Selection: Feature selection isn't about choosing data columns, but rather deciding on linguistic features like part-of-speech tags, dependency roles, or syntactic n-grams that might be useful for improving translation context and accuracy.
-
Pipeline Testing: Testing a machine translation pipeline involves ensuring that data flows correctly from input text preprocessing, through the translation model, to generating the output text. This includes validating the handling of different languages, long sentences, and maintaining context over paragraphs or documents.
It is important to note that in the deployment stage, you would need to construct inference pipelines that streamlines all of the above tasks.
4. Package Model
Model packaging often refers to the serialization and containerization of a model. Serialization involves converting the model into a format suitable for storage or transmission, while containerization involves bundling the serialized model with all required dependencies into a container for deployment.
Serialization
Model serialisation refers to the process of converting a model from its in-memory representation (e.g., objects, data structures) into a format suitable for storage or transmission.
It is important because it allows us to standardise the model format, making it easier to deploy and manage across different environments. Common formats include ONNX, PMML, and even pickle. Many ML frameworks have bespoke formats, making it easier to deploy/manage across different environments.
For example, TensorFlow SavedModel encapsulates weights, architecture, and signatures all in one file. PyTorch TorchScript similarly serialises PyTorch models into a TorchScript file that can be loaded for deployment.
Containerization
Model containerisation refers to the process of encapsulating the (often serialised) model and its dependencies within a container.
The container includes everything needed to run the model, including the application code, runtime environment, libraries, and dependencies.
The most common tool is Docker.
For this competition, serialization of your model is optional. However, you are required to package your model along with its dependencies into a Dockerfile.
Here is an example of the Dockerfile:
FROM --platform=linux/amd64 python:3.10.14-slim
WORKDIR /app
# Dependencies
COPY ./serve-requirements.txt .
RUN pip install --no-cache-dir -r serve-requirements.txt
# Trained model and definition with main script
COPY ./saved_model /app/saved_model
COPY ./main.py /app/main.py
# Set entrypoint
ENTRYPOINT ["python", "-m", "main"]
5. Local Deployment Test
To ensure your model has been packaged correctly, you can deploy the Docker container locally.
Tips
To streamline the debugging process, it's important to test your deployment locally before attempting to deploy it on the Highwind platform. This preliminary step can help you identify and resolve issues more efficiently.
For a step-by-step guide on how to do this, please refer to the following tutorial Deploy custom model. Additionally, check out the the provided example.
(Optional) Highwind's Pipeline
Starting in July, the Highwind team will enable testing using the Highwind Pipeline. This feature will assist you in creating portable and scalable machine learning workflows.
If you are interested in learning about and using the Highwind Pipeline, please join our Discord channel to receive updates.
Zindi Rules
If you are in the top 10 at the time the leaderboard closes, we will email you to request your code.
On receipt of email, you will have 48 hours to respond and submit your code following the guidelines detailed below. Failure to respond will result in disqualification:
- If your submitted code does not reproduce your score on the leaderboard, we reserve the right to adjust your rank to the score generated by the code you submitted.
- If your code does not run you will be dropped from the top 10. Please make sure your code runs before submitting your solution.
- Always set the seed. Rerunning your model should always place you at the same position on the leaderboard. When running your solution, if randomness shifts you down the leaderboard we reserve the right to adjust your rank to the closest score that your submission reproduces.
- Custom packages in your submission notebook will not be accepted. You may only use tools available to everyone i.e. no paid services or free trials that require a credit card.